Sounds like overkill, right? It is. Obviously, you don’t need a whole bunch of cloud services to build a simple web scraper, especially since there is already a lot of them out there. However, this describes my personal journey of exploring cloud-native development on AWS by building a simple, yet useful application.
The Goal
What I wanted to build was a web scraper that runs entirely on cloud infrastructure. More precisely, I wanted to build a scraper using Selenium WebDriver, because it should be able to scrape not only static HTML pages, but also dynamic, JavaScript-powered single-page apps. With this requirement in mind, a simple Python script incorporating requests or urllib is not sufficient anymore. Instead, you would need at least a headless browser (like Firefox, Chrome or the out-dated PhantomJS).
Example Use Case
To get a better idea of what I had been building, imagine the following use case. You are a student and your university provides a JavaScript-based website where exam results are published as soon as they are available. To retrieve your results you need to enter your student id and select a department from a drop-down list. You are curious about your grade in the most recent exam, but since you’re lazy, you do not want manually check the website every day. That’s where a totally over-engineered web scraper comes to play.
Requirements
Here are some notes on what the application was supposed to be able to do (and how) - just to get a slightly better understanding.
- Different crawl tasks are pre-defined as WebDriver scripts in Java.
- Users can add subscriptions for pre-defined crawling jobs. They will result in a certain crawl task being executed with certain parameters (e.g. form input field values to be filled by Selenium) at a regular interval (e.g. every 24 hours).
- When adding a subscription for a certain task (corresponding to a certain webpage), users provide their e-mail address and are getting notified once the scraper detects a change.
- The state of a web-site is persisted in the Dynamo item for the respective subscription and compared to the most recent state that is retrieved when the scraper runs.
Architecture
Below you can see a high-level overview of all components and the corresponding AWS services, as well as basic interactions between the components. Please note that the diagram is not proper UML, but it should help getting an idea of the overall architecture. And it looks kind of fancy at first sight.)
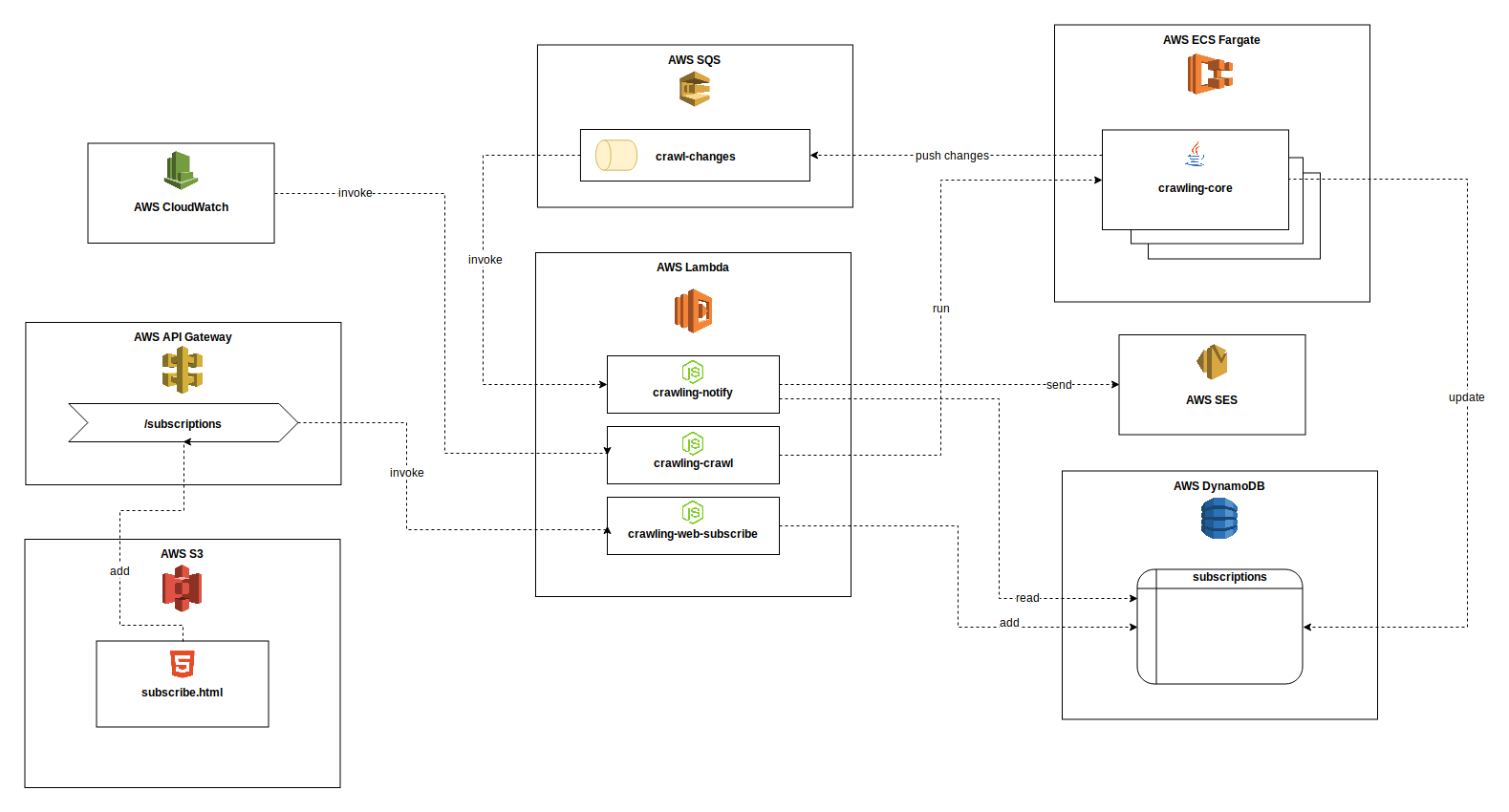
AWS services
The cloud services used are:
- AWS Lambda for Serverless NodeJS functions to perform stateless tasks
- AWS Fargate as an on-demand Docker container runtime to execute longer-running, more resource-intense tasks
- AWS DynamoDB as a schema-less data store to manage subscriptions and website states
- AWS SQS as a asynchronous messaging channel for communication between components and to trigger Lambdas
- AWS S3 to host a static HTML page containing a form to be used for adding new subscriptions thorugh a UI
- AWS API Gateway to provide an HTTP endpoint for adding new subscriptions. It is called by the “frontend”-side script and subsequently triggers a Lambda to add the new subscription to Dynamo.
- AWS CloudWatch to regularly trigger the execution of the scraper on Fargate in a crontab-like fashion
- AWS SES to send notification e-mails when something has changed
Components
Let’s take a very brief look at what the several components are doing.
crawling-core
This is essentially the core part of the whole application, the actual scraper / crawler. I implemented it as a Java command-line application, which has the WebDriver as a dependency to be able to interact with webpages dynamically.
The program is responsible for executing an actual crawling task itself, for detecting changes by comparing the task’s result to the latest state in the database, for updating the database item and for potentially pushing a change notification message to a queue.
Scraping tasks are defined as Java classes extending the AbstractTask class. For instance, you could create sub-classes AmazonPriceTask and ExamsResultsTask. While implementing these classes, you would essentially need to define input parameters (e.g. your student ID number to be filled in to a search form on the university website later on) for the crawling script and a series of commands in the run() method to be executed by WebDriver.
crawling-core is developed as a standalone Java command-line application, where the name of the task to be executed (e.g. EXAM_RESULT_TASK) and the input parameters (e.g. VAR_STUDENT_ID, VAR_DEPARTMENT_NAME) are provided as run arguments or environment variables.
In addition to the Java program, packaged as a simple JAR, we need a browser the WebDriver can use to browse the web. I decided to use Firefox in headless mode. Ultimately, the JAR and the Firefox binary are packaged together into a Docker images based on selenium/standalone-firefox and pushed to AWS ECR (AWS’ container registry).
To execute a scraping task, e.g. our ExamsResultsTask, AWS Fargate will pull the latest Docker image from the registry, create a new container from it, set the required input parameters as environment variables and eventually run the entrypoint, which is our JAR file.
λ crawling-crawl
… is a very simple Lambda function written in NodeJS, which is responsible for launching a crawling job. It is triggered regularly through a CloudWatch event. First, it fetches all crawling tasks from Dynamo. A crawling task is a unique combination of a task name and a set of input parameters. Afterwards it requests Fargate to start a new new instance of crawling-core for every task and passes the input parameters contained in the database item.
λ crawling-notify
… is another Lambda, which stands at the very end of one iteration of our crawling process. It is invoked through messages in the crawling-changes SQS queue and responsible for sending out notification e-mails to subscribers. It reads change information from the invoking event, including task name, the subscriber’s e-mail address and the task’s output parameters (e.g. your exam grade) and composes an e-mail message that eventually gets sent through the Simple E-Mail Service (SES).
λ crawling-web-subscribe
The last of our three Lambdas is not directly related to the crawling itself. Instead, it is used for handling HTTP requests sent by a user who wants to add a new subscription. Initiated by a simple script on an HTML page called subscribe.html, a POST is sent to the /subscriptions endpoint in the API Gateway, then forwarded to the crawling-web-subscribe and ultimately added to the Dynamo database as a new item in the subscriptions table.
Okay, cool. And now?
As I mentioned before, this project was rather a learning playground for me than a reasonable architecture for a web scraper. Although this one should, in fact, be quite scalable, you could definitely build a scraper script with much less effort. However, I learned a lot about cloud development and AWS specifically and I really like how easy things can be and how well all these different components play together. Maybe I was able to encourage the less cloud-experienced developers among you to start playing around with AWS (or some other cloud provider) as well and I hope you liked my (very spontaneously written) article.